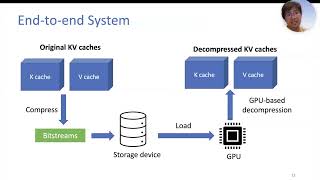
Media Summary: Try Voice Writer - speak your thoughts and let AI handle the grammar: The Large Language Models are powerful, but they have a massive bottleneck: memory overhead. When you feed an AI massive ... In this deep dive, we'll explain how every modern Large Language Model, from LLaMA to GPT-4, uses the
What Is Kv Cache Compression - Detailed Analysis & Overview
Try Voice Writer - speak your thoughts and let AI handle the grammar: The Large Language Models are powerful, but they have a massive bottleneck: memory overhead. When you feed an AI massive ... In this deep dive, we'll explain how every modern Large Language Model, from LLaMA to GPT-4, uses the Don't like the Sound Effect?:* *LLM Training Playlist:* ... Ever wonder how even the largest frontier LLMs are able to respond so quickly in conversations? In this short video, Harrison Chu ... Lex Fridman Podcast full episode: Thank you for listening ❤ Check out our ...
Is the "Memory Wall" finally crumbling? In this video, we dive deep into **TurboQuant**, a revolutionary framework that addresses ... Have you ever wondered how massive language models like DeepSeek-R1 and Qwen3 handle complex math problems without ... In this AI Research Roundup episode, Alex discusses the paper: 'TurboAngle: Near-Lossless MIT, NVIDIA, and Zhejiang University released TriAttention, achieving 50x In this AI Research Roundup episode, Alex discusses the paper: 'TriAttention: Efficient Long Reasoning with Trigonometric 00:00 Attention Is Geometry 00:53 TurboQuant Introduction 01:02 Two Problems with Standard Quantization 01:54 Hadamard ...
Google researchers have developed TurboQuant, a suite of advanced algorithms designed to significantly compress the ... As AI context windows expand to process entire codebases and massive documents, the Key-Value (