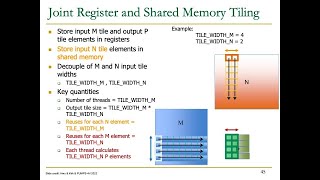
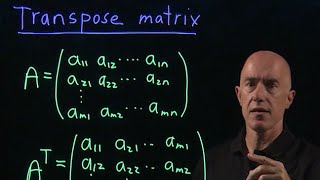Media Summary: Lecture 4 4 tiled matrix multiplication kernel UIUC ECE508/CS508 Spring 2019 - Manycore Parallel Algorithms (Textbook: Programming Massively Parallel Processors) Instructor - Prof. Wen-mei Hwu Playlist -
Lecture 4 4 Tiled Matrix - Detailed Analysis & Overview
Lecture 4 4 tiled matrix multiplication kernel UIUC ECE508/CS508 Spring 2019 - Manycore Parallel Algorithms (Textbook: Programming Massively Parallel Processors) Instructor - Prof. Wen-mei Hwu Playlist - This video is part of an online course, Intro to Parallel Programming. Check out the course here: ... This video explains how to find the determinant of a Definition of the transpose. How to take the transpose of the product of two
Project & Seminar, ETH Zürich, Fall 2022 Programming Heterogeneous Computing Systems with GPUs and other Accelerators ...