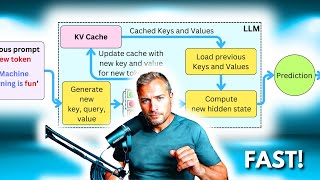
Media Summary: Try Voice Writer - speak your thoughts and let AI handle the grammar: The Ever wondered how large language models like GPT respond so fast without recomputing everything from scratch? In this video, I ... Explore NVIDIA Dynamo's capability to offload
Kv Cache Explained Speed Up - Detailed Analysis & Overview
Try Voice Writer - speak your thoughts and let AI handle the grammar: The Ever wondered how large language models like GPT respond so fast without recomputing everything from scratch? In this video, I ... Explore NVIDIA Dynamo's capability to offload This is a single lecture from a course. If you you like the material and want more context (e.g., the lectures that came before), check ... Ready to become a certified watsonx Generative AI Engineer? Register now and use code IBMTechYT20 for 20% off of your exam ... Don't like the Sound Effect?:* *LLM Training Playlist:* ...
The attention mechanism is known to be pretty Lex Fridman Podcast full episode: Thank you for listening ❤ Check out our ... Ever wonder how even the largest frontier LLMs are able to respond so quickly in conversations? In this short video, Harrison Chu ... Open-source LLMs are great for conversational applications, but they can be difficult to scale in production and deliver latency ... 00:00 Attention Is Geometry 00:53 TurboQuant Introduction 01:02 Two Problems with Standard Quantization 01:54 Hadamard ...





![KV Caching: Speeding up LLM Inference [Lecture]](https://i.ytimg.com/vi/_quDGLpNols/mqdefault.jpg)










![[CVPR2026] FlashCache](https://i.ytimg.com/vi/pkWj0dymyWs/mqdefault.jpg)


