Media Summary: This video explains how Distributed Data Parallel (DDP) and With the popularity of Large Language Models and the general trend of scaling up model and dataset sizes comes challenges in ... Build intuition about how scaling massive LLMs works. I cover two techniques for making LLM models train very fast,
How Fully Sharded Data Parallel - Detailed Analysis & Overview
This video explains how Distributed Data Parallel (DDP) and With the popularity of Large Language Models and the general trend of scaling up model and dataset sizes comes challenges in ... Build intuition about how scaling massive LLMs works. I cover two techniques for making LLM models train very fast, Eager to train your own or -4o model but running out of Discover how DDP harnesses multiple GPUs across machines to handle larger models and datasets, accelerating the training ... ... Cory Ye, Xuwen Chen & Sangkug Lym, NVIDIA
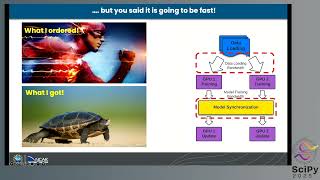
FSDP addresses memory capacity challenges by ... DDP or FSDP 21:12 Distributed Data Parallel 24:40 Model Parallel and ... advanced parallelization techniques, such as This talk dives into recent advances in PyTorch




![[Short Review] Fully Sharded Data Parallel: faster AI training with fewer GPUs](https://i.ytimg.com/vi/X8aSwVhiaLU/mqdefault.jpg)









![[Long Review] Fully Sharded Data Parallel: faster AI training with fewer GPUs](https://i.ytimg.com/vi/NiL7egqyJEI/mqdefault.jpg)
