Media Summary: Join the MLOps Community here: mlops.community/join // Abstract Getting the right LLM inference stack means choosing the right ... Best place to learn and practice system design Is your AI model fast enough for real users? In Part 3 of our AI Infrastructure series, we master Real-Time Inference, ensuring your ...
Exploring The Latency Throughput Cost - Detailed Analysis & Overview
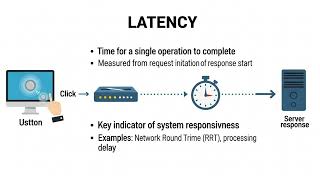
Join the MLOps Community here: mlops.community/join // Abstract Getting the right LLM inference stack means choosing the right ... Best place to learn and practice system design Is your AI model fast enough for real users? In Part 3 of our AI Infrastructure series, we master Real-Time Inference, ensuring your ... How do we serve AI models in production without breaking the bank or keeping users waiting? In this lecture, based on Chapter 9 ... The Hidden Constraints Behind Real AI Systems Your AI system works perfectly in a demo. But what happens when real users ... Although they may seem highly technical, you've already experienced both concepts - and why they matter - if you've ever done a ...
Welcome to Day 2! Today, we dive into the two most critical metrics that define the Scaling LLM applications in production often leads to skyrocketing API Deploying Large Language Models (LLMs) for inference is a complex yet rewarding process that requires balancing Amazon found that every 100 milliseconds of added