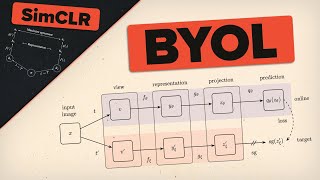
Media Summary: To try everything Brilliant has to offer—free—for a full 30 days, visit . You'll also get 20% off an annual ... In this tutorial, we will take a closer look at self-supervised Let's talk about the paper "Bootstrap Your Own Latent: A new approach to self-supervised
Contrastive Learning With Simclr Deep - Detailed Analysis & Overview
To try everything Brilliant has to offer—free—for a full 30 days, visit . You'll also get 20% off an annual ... In this tutorial, we will take a closer look at self-supervised Let's talk about the paper "Bootstrap Your Own Latent: A new approach to self-supervised For more information about Stanford's Artificial Intelligence programs visit: To follow along with the course, ... What do compressed neural networks forget? This paper shows how to utilize these lessons to improve ... tune it on the downstream task okay so that's
Get ready to revolutionize your AI knowledge with MIT's introductory course ( on Self-Supervised ... Notes ▭▭▭▭▭▭▭▭▭▭▭ Two small things I realized when editing this video - Presentation By Yuandong Tian from Meta for the Data The cross-entropy loss has been the default in This is video no. 5 in a series walking through Full paper: Presenter: Dan Fu Stanford University, USA Abstract: This ...