Media Summary: Llama.cpp Web UI + GGUF Setup Walkthrough and Model providers DON'T want you to see this video. The M5 Max just exposed the dirty secret of the cloud LLM economy: you're ... Can a modern LLM like llama 2 and llama 3 run on older MacBooks like MacBook Air M1, M2, and Intel Core i5? Sort of and i ...
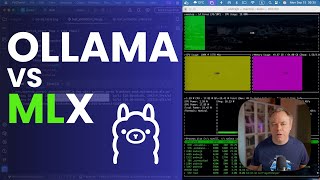
Mlx Vs Ollama On M4 - Detailed Analysis & Overview
Llama.cpp Web UI + GGUF Setup Walkthrough and Model providers DON'T want you to see this video. The M5 Max just exposed the dirty secret of the cloud LLM economy: you're ... Can a modern LLM like llama 2 and llama 3 run on older MacBooks like MacBook Air M1, M2, and Intel Core i5? Sort of and i ... I put a tiny MacBook Air between me and some ridiculously large local AI models... and it worked. Power Your Spring Essentials ... Best Deals on Amazon: MY TOP PICKS + INSIDER DISCOUNTS: I ... I run couple of tests with structured data extraction using newest Qwen3-VL model on Mac Mini
Best Deals on Amazon: MY TOP PICKS + INSIDER DISCOUNTS: I ... MacBook Pro M5 Max 128GB running local LLMs Speed Race Want to fine-tune AI models on your Mac without cloud services? As an ex- Which one can win? Test the token generating speed, the cost, the power consumption. ... The M5 Max MacBook Pro with 128GB of Unified Memory has officially landed in the studio, and it is a total game-changer for ... How fast are they? Demo of MacMini runnning some of the state of art AI models. ...
DeepSeek compared running locally - various model sizes and quantizations on M1, M2, M3,